// [rev] fsvm 2 (66 solves)
// Writeup author: @toni
// Challenge author: @matpro
Challenge description
I wrote an improved version of my previous VM, but it's still not capable of printing good descriptions.
Table of contents
Introduction
This was a really fun (and just a tiny bit infuriating) VM reversing challenge.
This writeup is pretty beginner friendly and very detailed, more advanced readers might want to skip to the TL;DR at the end.
First impressions
Similar to the original fsvm, we are given a bytecode program and a vm to execute it with.
This time however, when running the program, we only get a "File not found" error. Let's run it with strace to find out what it's trying to open.
$ strace ./vm bytecode 2>&1 | grep "openat" // just the usual setup stuff openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libstdc++.so.6", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libgcc_s.so.1", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libc.so.6", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libm.so.6", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "bytecode", O_RDONLY) = 4 openat(AT_FDCWD, "regs/reg0", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 5 openat(AT_FDCWD, "regs/reg1", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 5 openat(AT_FDCWD, "regs/reg0", O_WRONLY|O_CREAT|O_APPEND, 0666) = 5 openat(AT_FDCWD, "regs/reg0", O_WRONLY|O_CREAT|O_APPEND, 0666) = 5 openat(AT_FDCWD, "regs/reg1", O_WRONLY|O_CREAT|O_APPEND, 0666) = 5 ... // continues for ~500 more lines
If you've solved the first fsvm, this will look familiar. It's using the regs/ folder to store some variables.
Let's filter out the useless stuff:
$ strace ./vm bytecode 2>&1 | grep "openat" | grep -v "regs/reg" openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libstdc++.so.6", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libgcc_s.so.1", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libc.so.6", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "/usr/lib/libm.so.6", O_RDONLY|O_CLOEXEC) = 4 openat(AT_FDCWD, "bytecode", O_RDONLY) = 4 openat(AT_FDCWD, "flag.txt", O_RDONLY) = -1 ENOENT (No such file or directory)
Alright, it's trying to open up flag.txt, so let's put something there:
$ echo "openECSC{hello_world}" > flag.txt $ ./vm bytecode /usr/src/.../include/bits/basic_string.h: 1246: ... Assertion '__pos <= size()' failed. [1] 6834 IOT instruction (core dumped) ./vm_orig bytecode
Oops, it's too short. Lets make it longer.
$ echo "openECSC{hello_world_aaaaaaaaaaaaaaa}" > flag.txt $ ./vm bytecode Wrong!
That's great, now lets figure out how it works!
Reversing
It's time to open up the binary in your reversing tool of choice. I'm a big fan of cutter, so that's what I'll use, but anything should work.
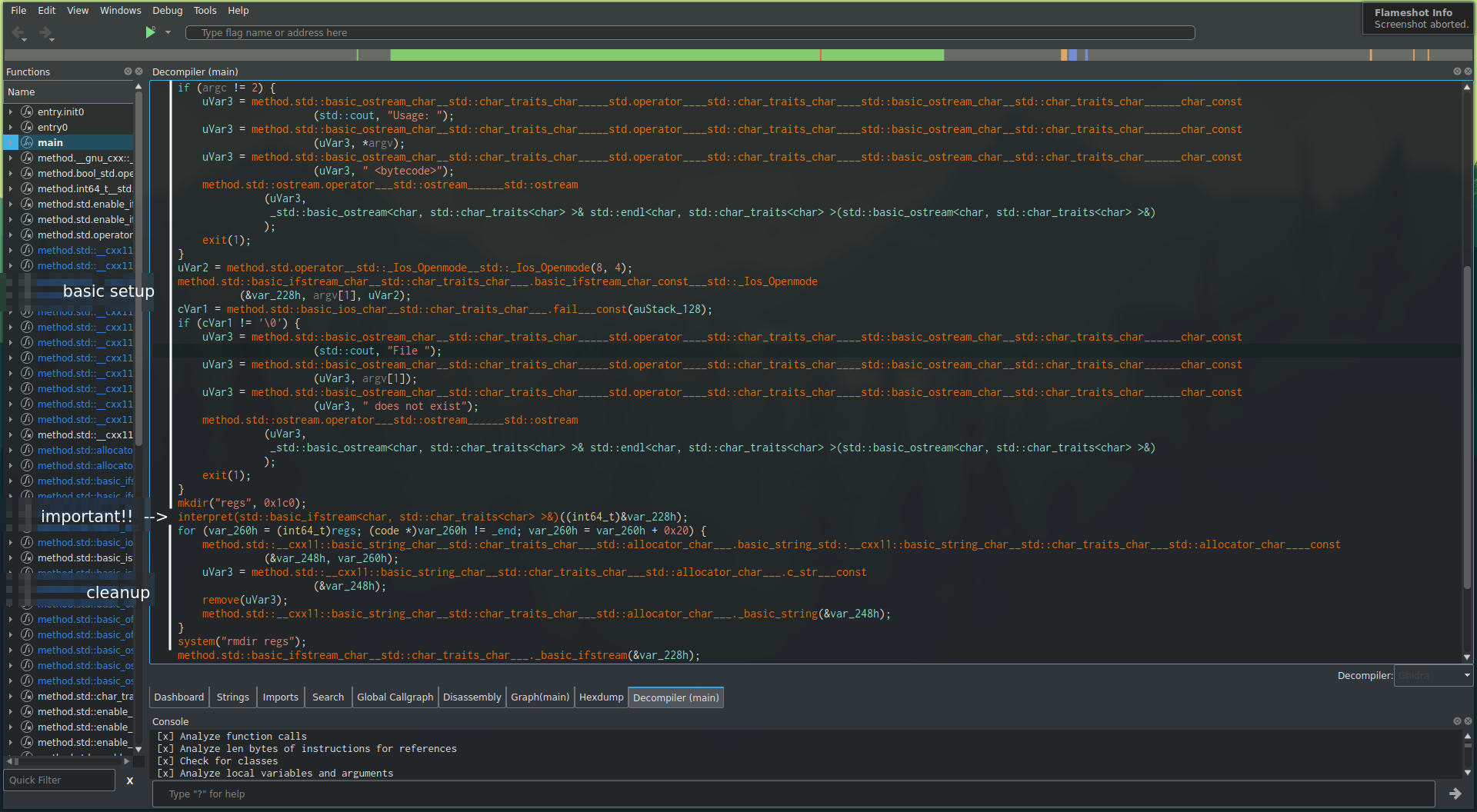
After navigating over to the function main, we can see some setup stuff:
- loading the bytecode
- creating the
regs/folder - calling
interpret()to run the bytecode
And also some cleanup at the end:
- deleting all the files in
regs/ - deleting the folder itself
Let's patch it to not delete the registers after exiting.
- open up main() in disassembly view
- change the calls to
remove()andsystem()to no-ops- (located at
0x00004aeaand0x00004b08), right-click > Edit > Nop Instruction
- (located at
Let's also make a tiny shell alias to print out the state of the registers at the end of the program.
$ alias printregs='for x in regs/*; do echo -ne "\n$x - " && cat $x; done' $ ./vm bytecode Wrong! $ printregs regs/reg0 - 0 regs/reg1 - 112 regs/reg2 - 4928 regs/reg3 - -01 regs/reg4 - 191324 regs/reg6 - 2 regs/reg7 - 10 regs/reg8 - o regs/reg9 - openECSC{hello_world_aaaaaaaaaaaaaaa} regs/rega - 01 regs/regb - ! regs/regc - 191324 regs/regf - Wrong!
Cool, but nothing immediately pops out as interesting. We have our flag in reg9, and some boring numbers in the other registers.
Let's look at the bytecode, maybe it can tell us something interesting.
The bytecode
$ xxd bytecode | head 00000000: 4041 5200 5200 5201 5401 5100 0100 5200 @AR.R.R.T.Q...R. 00000010: 5401 5100 0100 4151 0001 013e 0000 5301 T.Q...AQ...>..S. 00000020: 5301 5201 4252 0251 0102 0142 5101 0202 S.R.BR.Q...BQ... 00000030: 5101 0201 5101 0201 4251 0102 0252 0153 Q...Q...BQ...R.S 00000040: 0251 0102 013e 0101 3f00 0100 4142 5202 .Q...>..?...ABR. 00000050: 5402 5201 5201 5102 0101 5201 4343 5101 T.R.R.Q...R.CCQ. 00000060: 0303 5102 0202 5102 0202 5102 0101 3e01 ..Q...Q...Q...>. 00000070: 013f 0001 0042 5202 5102 0303 5102 0303 .?...BR.Q...Q... 00000080: 3e03 013f 0001 0054 0241 5103 0101 5103 >..?...T.AQ...Q. 00000090: 0101 5103 0101 5102 0101 5102 0101 5102 ..Q...Q...Q...Q.
We have some printable ASCII characters, and some other unprintable characters.
It's also useful to notice that the unreadable characters are all low: 0x00 to 0x0f.
After a bit of looking at interpret() in the decompiler, we can notice some important stuff:
- The high (printable) bytes (
0x28-0x57) represent instructions, - and the low bytes (
0x00-0x0f) adress the registers, arguments to the instructions
Great, but what do the instructions do?
Instructions analysis
It's probably smart to start with the instructions at the beginning of bytecode.
Let's look at the instructions 0x40 and 0x41, the first two instructions used.
Because Ghidra's / Cutter's Ghidra plugin decompilation looks pretty cluttered when working with C++, I'll use the Decompiler Explorer - dogbolt.org.
Dogbolt allows us to look at multiple different decompilation tools at the same time, and pick which one we like the most. If you haven't used it before, you should definitely check it out. In the next few paragraphs, I'll interchangeably use the decompilations made by BinaryNinja and Hex-Rays (IDA Pro), as they look the cleanest in my opinion.
0x4_ instructions
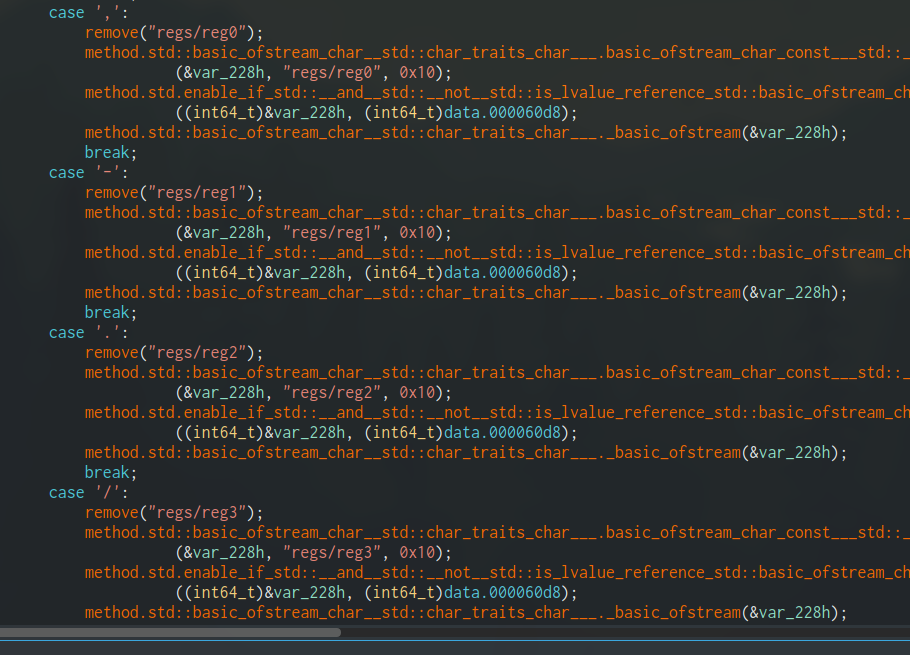
All of the 0x4_ instructions do the same thing, just for different registers:
case 0x40: { remove("regs/reg0"); std::ofstream::ofstream(&var_228, "regs/reg0"); std::ostream::put(&var_228, 0x30); std::ofstream::~ofstream(&var_228); break; } case 0x41: { remove("regs/reg1"); ... // continues all the way to case 0x4f and removing regf
It's overwriting the file contents with 0x30 ('0').
Let's try to use the instructions ourselves:
$ rm -r regs; echo -ne "\x40\x41" > bytes; ./vm bytes; printregs regs/reg0 - 0 regs/reg1 - 0
Pretty simple so far. Let's write a simple script that will replace the instructions we know with pseudocode.
First I'll convert it to hex to make my life a bit easier:
$ xxd -ps -c 1 bytecode > hexcode $ head hexcode 40 41 52 00 52 00 52 01 54 01
# translate.py import re with open("hexcode", "r") as f: data = f.read() # Move the register params to the same line as the instruction data = re.sub(r"\n0", r" 0", data) # set reg to 0 data = re.sub(r"4(.)\n", r"r\1 = 0\n", data)
# 2>/dev/null stops python from complaining about pipes $ py translate.py 2>/dev/null | head r0 = '0' r1 = '0' 52 00 52 00 52 01 54 01 51 00 01 00 52 00 54 01 51 00 01 00
That's a great start, let's move on.
0x52
Next up, We'll look at 0x52.
52 00
It takes a single input register. Let's just try using it and see what happens.
$ rm -r regs; echo -ne "\x52\x00" > bytes; ./vm bytes; printregs regs/reg0 - 1
$ rm -r regs; echo -ne "\x52\x00\x52\x00" > bytes; ./vm bytes; printregs regs/reg0 - 11
Okay, sure. It's working with strings.
$ rm -r regs; mkdir regs; echo -n "hello world" > regs/reg0; echo -ne "\x52\x00" > bytes; ./vm bytes; printregs regs/reg0 - hello world1
That's good I guess. On to the next one.
0x51
This one takes three arguments. Let's just try giving it 0, 1 and 2:
$ rm -r regs; echo -ne "\x51\x00\x01\x02" > bytes; ./vm bytes; printregs regs/reg2 - 280889212452368
Oooh, looks like some fun *undefined behaviour*. Let's initialize the registers first:
$ rm -r regs $ echo -ne "\x52\x00\x52\x01\x52\x02\x51\x00\x01\x02" > bytes # r0 = 0; r1 = 0; r2 = 0; r3 = r1 + r2 $ ./vm bytes; printregs regs/reg0 - 1 regs/reg1 - 1 regs/reg2 - 2
Very nice, that looks like addition to me. And the decompilation agrees:
case 'Q': // read an integer from the first register (and save it into v25) std::istream::get(a1, &v23); std::ifstream::basic_ifstream(v29, (char *)®s + 32 * v23, 8LL); std::operator>><std::ifstream,long long &>((__int64)v29, (__int64)&v25); std::ifstream::~ifstream(v29); // read a second integer from the other param (saved into v26) std::istream::get(a1, &v23); std::ifstream::basic_ifstream(v29, (char *)®s + 32 * v23, 8LL); std::operator>><std::ifstream,long long &>((__int64)v29, (__int64)&v26); std::ifstream::~ifstream(v29); // add them together v25 += v26; // write the sum to r3 std::istream::get(a1, &v23); v6 = (const char *)std::string::c_str((char *)®s + 32 * v23); remove(v6); std::ofstream::basic_ofstream(v29, (char *)®s + 32 * v23, 16LL); std::operator<<<std::ofstream,long long>((__int64)v29, &v25); std::ofstream::~ofstream(v29); goto LABEL_66;
Let's add both 0x51 and 0x52 to the translator:
# append '1' data = re.sub(r"52 0(.)", r"r\1 = r\1 + '1'", data) # addition data = re.sub(r"51 0(.) 0(.) 0(.)", r"r\3 = r\1 + r\2", data)
$ py translate.py 2>/dev/null | head -n 20 r0 = 0 r1 = 0 r0 = r0 + '1' r0 = r0 + '1' r1 = r1 + '1' 54 01 r0 = r0 + r1 r0 = r0 + '1' 54 01 r0 = r0 + r1 r1 = 0 r1 = r0 + r1 3e 00 00 53 01 53 01 r1 = r1 + '1' r2 = 0 r2 = r2 + '1' r1 = r1 + r2 r2 = 0
It's already coming together quite nicely.
The rest of the owl
Doing the rest of the instructions was quite tedious, not gonna lie. It was just more of the same: reading the decompilation to get a general idea and writing mini-bytecodes to check if it's right.
Here are all of the instructions:
-
0x40-0x4f- sets corresponding register to 0 -
0x51 <a> <b> <c>- additionc = a + b -
0x52 <a>- appends 1 -
0x53 <a>- pop the last character -
0x54 <a>- negate -
0x55- prints outrfto stdout -
0x56- reads a file namedr0intor0 -
0x57exits -
0x2c-0x3bclear the registersr0-rf -
0x3d <a> <b>- the ord function:b = ord(a[-1]) -
0x3e <a> <b>- the chr function:b = chr(a % 256) -
0x3f <a> <b> <c>- string concatenationc = f"{a}{b}" -
0x28- jmp - increments the instruction pointer byra -
0x29- je - jumps byraifrb == rc -
0x2a- jne - jumps byraifrb != rc -
0x2b- jb - jumps byraifrb < rc
Some are skipped because they aren't used in the binary and we don't care about them.
The interpreter
Alright. Now our bytecode looks all nice and pretty, but we have no way of running the pseudo-python we've generated. The jump offsets are calculated dynamically and I don't want to do that. This means the best way to understand the bytecode is to execute it ourselves. We now know what all the instructions mean, shouldn't be too difficult to write an interpreter.
You can find the interpreter in run.py. It's really simple.
It has:
- a dictionary for the registers
- an instruction pointer named
ptr - and a match-case for all the different instructions
Now we can start debugging. I started by printing out all the jumps/conditionals:
$ py run.py bytecode 2>/dev/null | head 322: JUMPING by 342 (to 664) IF openECSC{hello_world_aaaaaaaaaaaaaaa} != (-1) 715: JUMPING by -7 (to 708) IF openECSC{hello_world_aaaaaaaaaaaaaaa} != () 715: JUMPING by -7 (to 708) IF openECSC{hello_world_aaaaaaaaaaaaaaa != () 715: JUMPING by -7 (to 708) IF openECSC{hello_world_aaaaaaaaaaaaaa != () ... 715: JUMPING by -7 (to 708) IF ope != () 715: JUMPING by -7 (to 708) IF op != () 715: JUMPING by -7 (to 708) IF o != () 715: JUMPING by -7 (to 708) IF != () 772: JUMPING by 6 (to 778) IF 37 == 37
It starts out by looping through the string, and then checking if 37 == 37. That looks good, our flag is 37 characters, so it's probably checking that the length is right.
After that, we see this:
874: JUMPING by -14 (to 860) IF 0 < (73) 874: JUMPING by -14 (to 860) IF 0 < (72) 874: JUMPING by -14 (to 860) IF 0 < (71) 874: JUMPING by -14 (to 860) IF 0 < (70) 874: JUMPING by -14 (to 860) IF 0 < (69) 874: JUMPING by -14 (to 860) IF 0 < (68) 874: JUMPING by -14 (to 860) IF 0 < (67) 874: JUMPING by -14 (to 860) IF 0 < (66) 874: JUMPING by -14 (to 860) IF 0 < (65) 874: JUMPING by -14 (to 860) IF 0 < (64) ...
It's counting down and doing something. Let's print out the registers to see what it's doing:
874: JUMPING by -14 (to 860) IF 0 < (73) {'r0': '73', 'r1': '125', 'r2': '125', ..., 'rb': '0', 'rc': '73', ..., 'ra': '-14'} 874: JUMPING by -14 (to 860) IF 0 < (72) {'r0': '72', 'r1': '125', 'r2': '250', ..., 'rb': '0', 'rc': '72', ..., 'ra': '-14'} 874: JUMPING by -14 (to 860) IF 0 < (71) {'r0': '71', 'r1': '125', 'r2': '375', ..., 'rb': '0', 'rc': '71', ..., 'ra': '-14'} 874: JUMPING by -14 (to 860) IF 0 < (70) {'r0': '70', 'r1': '125', 'r2': '500', ..., 'rb': '0', 'rc': '70', ..., 'ra': '-14'} 874: JUMPING by -14 (to 860) IF 0 < (69) {'r0': '69', 'r1': '125', 'r2': '625', ..., 'rb': '0', 'rc': '69', ..., 'ra': '-14'}
Looks like it's adding r1 to r2 in a loop, r0 times.
That's just multiplication, lets clean up the logs:
jmps = set() ... case 0x2b: loc = ptr + int(regs['ra']) # print(f"{ptr}: JUMPING by {regs['ra']} (to {loc}) IF {regs['rb']} < ({regs['rc']})") if not ptr in jmps: jmps.add(ptr) # the loop runs n+1 times, aint that print(f"{regs['r2']} = {int(regs['r0'])+1} * {regs['r1']}") print(regs)
And the output is now much cleaner:
r2 = 74 * 125 r2 = 46 * 97 r2 = 70 * 97 r2 = 79 * 97 r2 = 58 * 97 r2 = 39 * 97 r2 = 41 * 97 r2 = 26 * 97 r2 = 46 * 97 r2 = 1 * 97 r2 = 79 * 97 r2 = 1 * 97 r2 = 27 * 97 r2 = 66 * 97 r2 = 34 * 97 r2 = 83 * 97 r2 = 97 * 95 r2 = 35 * 100 r2 = 94 * 108 r2 = 79 * 114 r2 = 37 * 111 r2 = 17 * 119 r2 = 76 * 95 r2 = 59 * 111 r2 = 97 * 108 r2 = 95 * 108 r2 = 1 * 101 r2 = 70 * 104 r2 = 26 * 123 r2 = 28 * 67 r2 = 99 * 83 r2 = 1 * 67 r2 = 95 * 69 r2 = 51 * 110 r2 = 10 * 101 r2 = 61 * 112 r2 = 44 * 111 3907: JUMPING by 0112710 (to 116617) IF 172921 != (194900)
Solution
Now those 97's look familiar. If we check the ASCII table, we can see that it corresponds to the letter a. Our test flag also has a bunch of a's!
After converting the second param to a char:
r2 = 74 * } r2 = 46 * a r2 = 70 * a r2 = 79 * a r2 = 58 * a r2 = 39 * a r2 = 41 * a r2 = 26 * a r2 = 46 * a r2 = 1 * a r2 = 79 * a r2 = 1 * a r2 = 27 * a r2 = 66 * a r2 = 34 * a r2 = 83 * a r2 = 97 * _ r2 = 35 * d r2 = 94 * l r2 = 79 * r r2 = 37 * o r2 = 17 * w r2 = 76 * _ r2 = 59 * o r2 = 97 * l r2 = 95 * l r2 = 1 * e r2 = 70 * h r2 = 26 * { r2 = 28 * C r2 = 99 * S r2 = 1 * C r2 = 95 * E r2 = 51 * n r2 = 10 * e r2 = 61 * p r2 = 44 * o 3907: JUMPING by 0112710 (to 116617) IF 172921 != (194900)
It's the flag we inputted, but backwards! Let's also bring back the print(regs):
r2 = 74 * } {'r0': '73', 'r1': '125', 'r2': '125', 'r3': '-01', 'r4': '0', ...} r2 = 46 * a {'r0': '45', 'r1': '97', 'r2': '97', 'r3': '-01', 'r4': '9250', ...} r2 = 70 * a {'r0': '69', 'r1': '97', 'r2': '97', 'r3': '-01', 'r4': '13712', ...} r2 = 79 * a {'r0': '78', 'r1': '97', 'r2': '97', 'r3': '-01', 'r4': '20502', ...}
It looks like it's adding everything up into r4.
The last r4 we see printed is 190016, and after adding 44 * 111 ('o'), we get 194900, That same number was in a conditional here:
3907: JUMPING by 0112710 (to 116617) IF 172921 != (194900) Wrong! done executing
What if we don't want to be wrong, and ignore the jump? Will it print Correct instead?
if regs['rb'] != regs['rc'] and loc != 116617:
Now we get a whole bunch of output. After it's cleaned up a bit, it looks like this:
74, 46, 70, 79, 58, 39, 41, 26, 46, 1, 79, 1, 27, 66, 34, 83, 97, 35, 94, 79, 37, 17, 76, 59, 97, 95, 1, 70, 26, 28, 99, 1, 95, 51, 10, 61, 44, 3907: JUMPING by 0112710 (to 116617) IF 172921 != (194900) 48, 74, 4, 92, 1, 26, 42, 94, 78, 44, 80, 62, 61, 27, 80, 48, 38, 46, 32, 92, 98, 66, 4, 7, 6,61, 96, 71, 3, 32, 70, 94, 72, 60, 45, 9, 45, 6996: JUMPING by 109621 (to 116617) IF 165441 != (187957) ... 62, 46, 74, 61, 77, 73, 82, 30, 53, 14, 66, 11, 79, 99, 75, 31, 58, 56, 39, 34, 75, 25, 6, 72,71, 95, 45, 35, 79, 75, 59, 21, 55, 47, 58, 55, 78, 91704: JUMPING by 24913 (to 116617) IF 188831 != (208097) 28, 45, 2, 5, 49, 37, 67, 13, 44, 29, 64, 97, 6, 34, 49, 63, 10, 32, 59, 12, 68, 29, 65, 52, 86, 40, 32, 57, 17, 90, 98, 96, 41, 92, 80, 3, 12, 94800: JUMPING by 21817 (to 116617) IF 151273 != (165076) 41, 56, 88, 22, 54, 28, 26, 68, 47, 91, 48, 28, 3, 69, 49, 78, 42, 67, 81, 34, 49, 11, 71, 25,19, 2, 23, 61, 29, 39, 77, 38, 99, 91, 16, 19, 3, 97899: JUMPING by 016259 (to 114158) IF 149344 != (164912)
After that jump, our interpreter crashes. Here's what python says:
0, Traceback (most recent call last): File "/home/tonik/proj/openecsc/fsvm2/run_wrk.py", line 71, in <module> regs[reg_1] = str(ord(regs[reg_0][-1])) ~~~~~~~~~~~^^^^ IndexError: string index out of range
Fun edge case. I wonder if the compiled vm binary handles it better?
// set r0 to '', then try reading a char from r0 $ rm -r regs; echo -ne "\x2c\x3d\x00\x01" > bytes; ./vm bytes; printregs /usr/src/debug/gcc/gcc-build/x86_64-pc-linux-gnu/libstdc++-v3/include/bits/basic_string.h:1246: std::__cxx11::basic_string<_CharT, _Traits, _Alloc>::reference std::__cxx11::basic_string<_CharT, _Traits, _Alloc>::operator[](size_type) [with _CharT = char; _Traits = std::char_traits<char>; _Alloc = std::allocator<char>; reference = char&; size_type = long unsigned int]: Assertion '__pos <= size()' failed. [1] 15088 IOT instruction (core dumped) ./vm bytes regs/reg0 - regs/reg1 -
That's so cool. Let's ignore that last jump as well:
... 97899: JUMPING by 016259 (to 114158) IF 149344 != (164912) // used to crash here 77, 58, 65, 44, 7, 33, 79, 45, 51, 28, 39, 17, 9, 24, 78, 10, 47, 73, 3, 70, 33, 70, 25, 93, 66, 24, 83, 29, 7, 4, 18, 28, 41, 45, 21, 56, 66, 100976: JUMPING by 15641 (to 116617) IF 145154 != (160440) 14, 51, 4, 7, 26, 23, 48, 2, 65, 8, 33, 70, 47, 98, 7, 75, 85, 8, 24, 68, 25, 20, 76, 98, 27, 25, 32, 98, 94, 42, 95, 80, 77, 89, 17, 87, 89, 104086: JUMPING by 12531 (to 116617) IF 167698 != (182034) 66, 3, 31, 95, 6, 99, 99, 98, 85, 70, 48, 40, 65, 37, 79, 44, 32, 55, 6, 93, 2, 39, 43, 60, 85, 1, 19, 50, 100, 61, 36, 80, 26, 44, 29, 9, 82, 107163: JUMPING by 9454 (to 116617) IF 172352 != (191666) 72, 66, 36, 80, 36, 44, 24, 10, 17, 19, 69, 51, 86, 88, 95, 73, 96, 13, 85, 15, 87, 19, 100, 51, 96, 41, 60, 50, 42, 34, 32, 92, 29, 96, 77, 37, 49, 110358: JUMPING by 6259 (to 116617) IF 187042 != (206648) 48, 5, 72, 84, 11, 33, 87, 22, 93, 100, 59, 26, 21, 29, 97, 10, 86, 10, 9, 3, 49, 59, 47, 25, 57, 34, 25, 95, 29, 6, 5, 80, 8, 98, 76, 90, 33, 113389: JUMPING by 3228 (to 116617) IF 155223 != (173565) 34, 18, 26, 84, 76, 99, 1, 86, 87, 69, 21, 42, 65, 57, 71, 59, 15, 70, 15, 61, 73, 88, 76, 2, 61, 89, 47, 28, 47, 52, 33, 39, 13, 15, 5, 33, 28, 116410: JUMPING by 207 (to 116617) IF 164628 != (179115) Correct! Reached an exit instruction
We get some more numbers/checks, and, after ignoring all of them, the program prints out Correct!.
If we count how many equality checks/jumps we do, we get 37.
That's the number of characters in our flag!
To recap:
- our flag is 37 characters
- we have 37 checks in this form
a*flg_0 + b*flg_1 + c*flg_2 + ... = x - if we pass all of the checks, our flag is correct
You'll probably notice this looks a lot like a system of equations. And that's exactly what it is!
We can use np.linalg.solve to solve it.
We need to store all of the multipliers in a matrix and all the sums into a vector. Like this:
... matrix = [] current_row = [] res_vec = [] ... case 0x2a: res_vec.append(int(regs['rb'])) matrix.append(current_row) current_row = [] ... case 0x2b: if not ptr in jmps: jmps.add(ptr) current_row.append(int(regs['r0'])+1) ... print("----------") print(matrix) print("----------") print(res_vec)
We have a bit of trash at the start due to some unrelated jumps, but after cleaning that up, we can finally get our flag:
... print("----------") print(matrix[39:]) print("----------") print(res_vec[39:]) print("----------") import numpy as np flag_vec = np.linalg.solve(matrix[39:], res_vec[39:]) print("".join([chr(round(x)) for x in flag_vec[::-1]]))
I hope you enjoyed the writeup!
TL;DR
This is the challenge:
- a compiled binary and some bytecode
- the binary runs the bytecode
- it prints out
Wrong!
Here's what we did to solve it:
- Decompile the binary and notice it stores registers under
regs/, but it deletes them at the end - Patch it to not delete the registers at the end
- Figure out what the instructions do using dogbolt and by writing our own bytecode for the vm
- Create a script to translate the bytecode into some pseudo-python
- Create a Python interpreter for the bytecode
When we had the interpreter, we had to:
- Print the conditional jumps
- Notice the flag needs to be 37 characters
- Notice it multiplies some numbers and adds them up
- Also notice the conditional jump (
rb!=rc) which jumps to the end - Ignore them in the code if they would jump to printing "Wrong!"
- Print out the constants
And finally:
- Notice it's a system of equations with the bytes in flag.txt as variables
- Use numpy's
np.linalg.solveto solve it and get the correct flag - profit